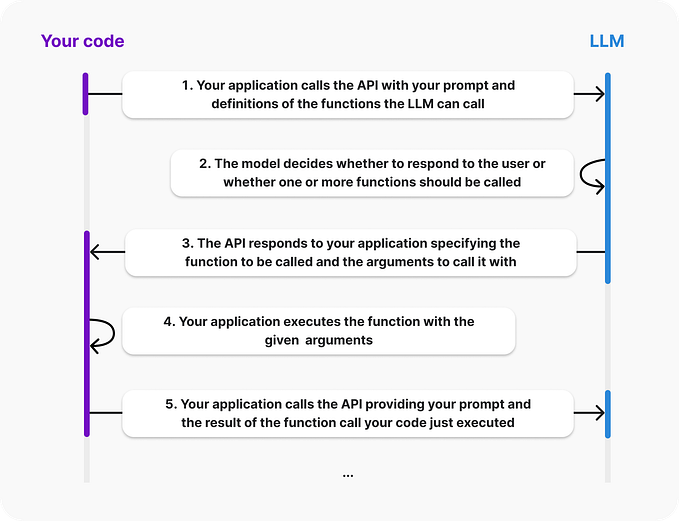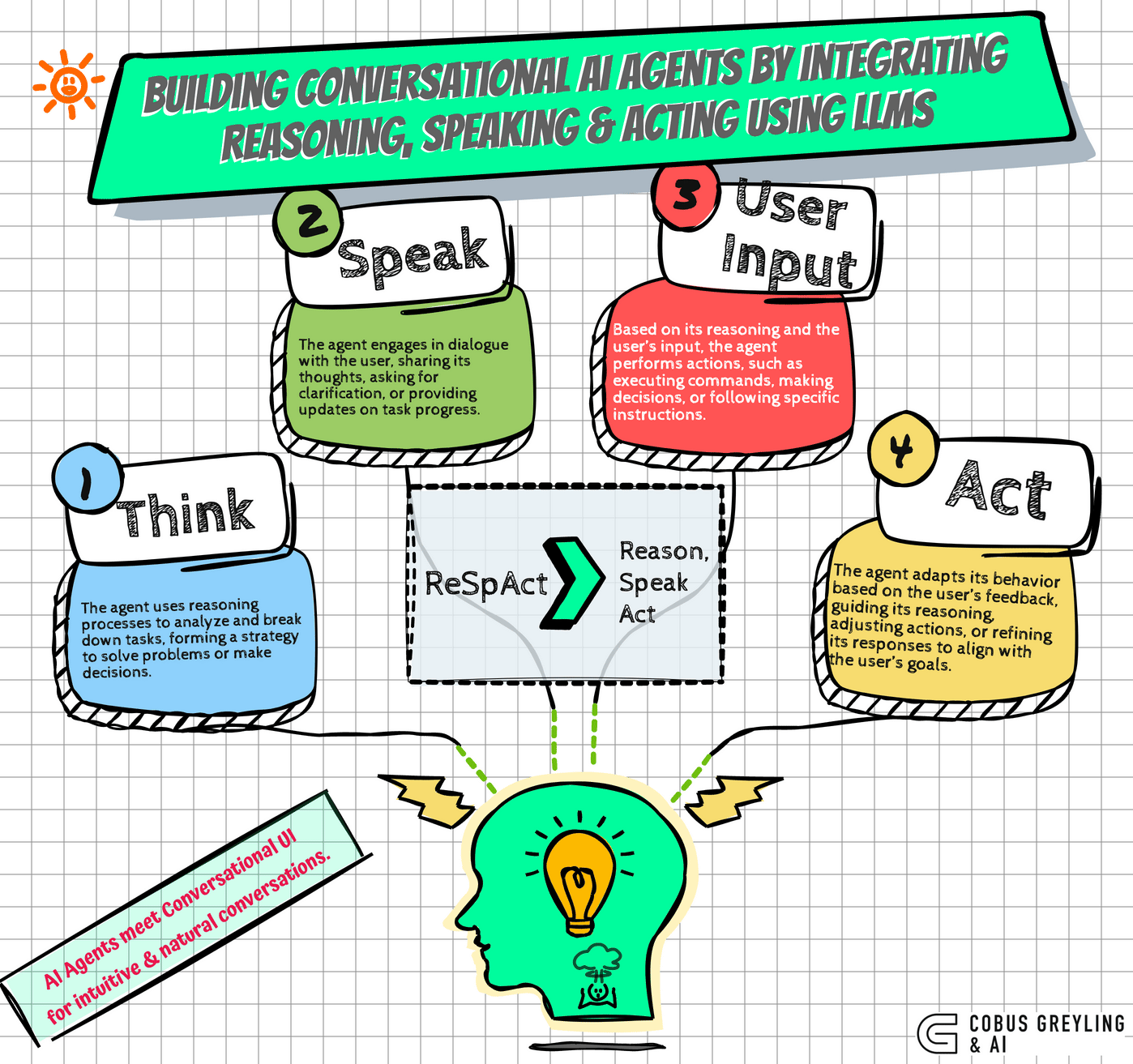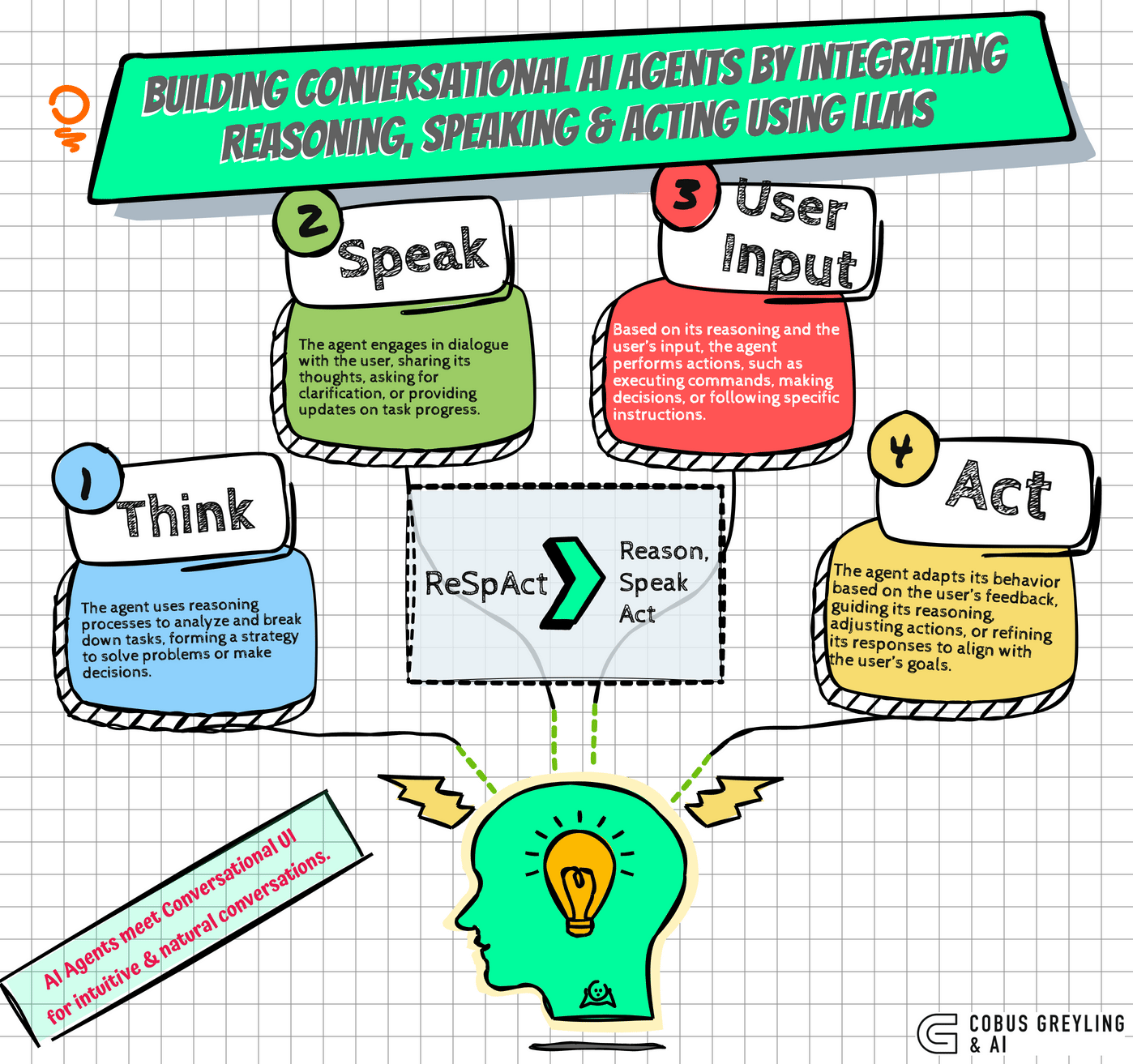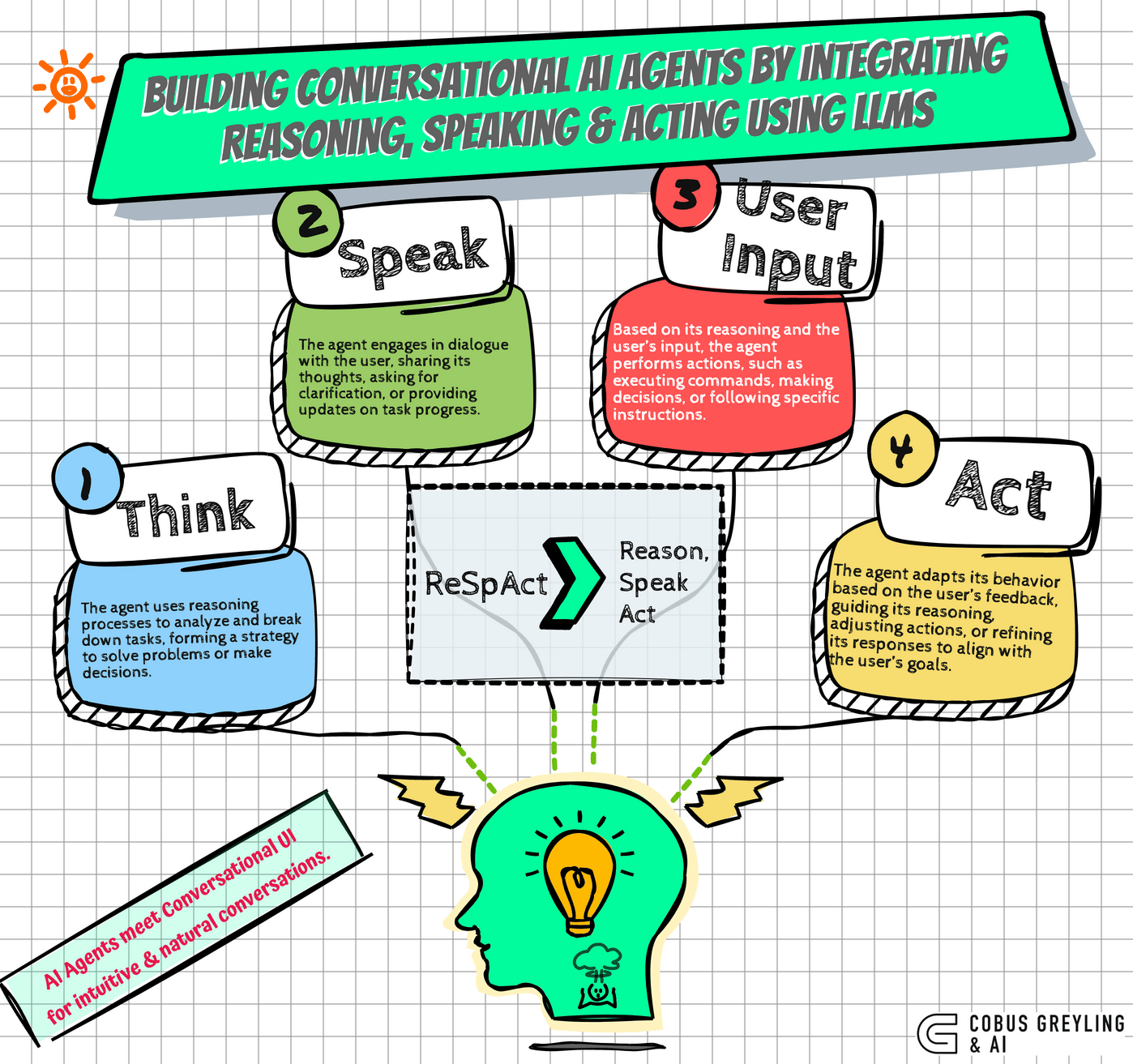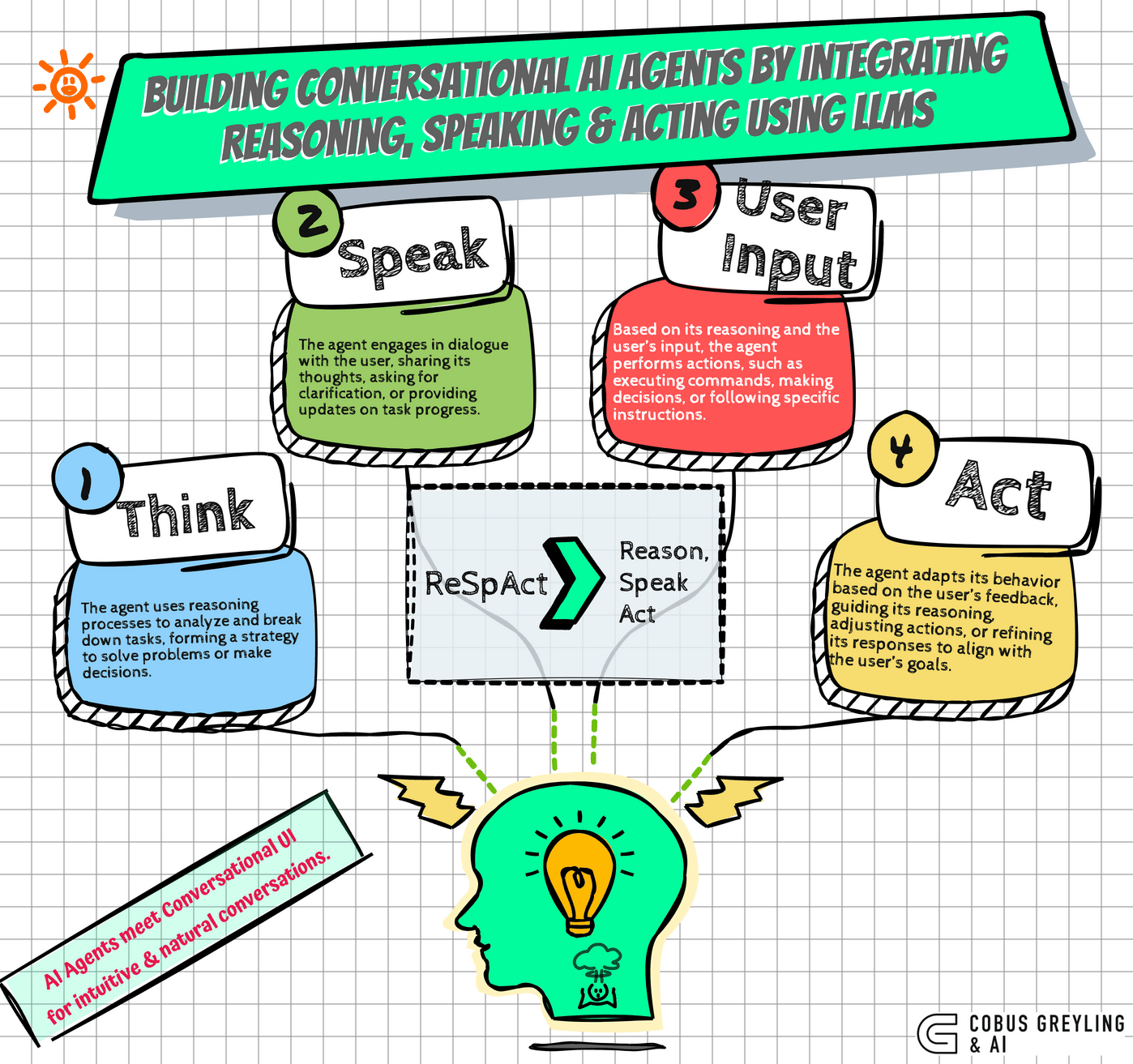
Just based on a simple description of functions, OpenAI’s function calling API can convert user utterances into function representations with remarkable accuracy. This completely eliminates the need to label a large set of examples and train a model for each new service to be exposed, significantly reducing the costs associated with the initial development of the dialog understanding module.
Unfortunately, there is no native provision in the API to address potential understanding issues. Nevertheless, language expression is notoriously long-tailed and dynamic, with new and unexpected variations constantly emerging. Hence, the ability to hotfix understanding issues in a cost-effective way is crucial for operating a chatbot.
Why existing fix does not work?

Under function calling or prompt engineering in general, the common ways to address understanding issues are quiet limited. Regrettably, none of these options prove to be cost-effective:
- Trying different prompts or function descriptions. While quite lightweight, this choice offers limited room for further improvement once a reasonable prompt is found.
- Fine-tuning the LLMs. This is a lot more effective and useful in certain scenarios, but it represents a significant undertaking involving data labeling and the tuning process, which only a few teams have the know-how and thus can manage.
- Improving LLMs by performing more pre-training, using larger models, etc. In nearly all use cases, it’s advisable to steer clear of this choice as it represents a substantial undertaking. Creating a high-performing foundational model is never a small feat, given the technical challenges and the high cost and time required.
Wait, we only use function descriptions?
The main signal that the function calling API uses to match user utterances with functions is the function description. It’s remarkable that this alone enables ChatGPT to perform well.
However, this approach completely overlooks the potential benefits of using examples. In fact, before the advent of instruction-tuned LLMs that made prompt engineering an effective approach for problem-solving, labeled examples that mapped the input to the desired output were the primary means of teaching machines to tackle challenging tasks that lacked algorithmic solutions. In practice, prompt engineering can also make use of labeled examples through a process known as in-context learning. Despite its name, this approach doesn’t involve updating the model weights, making it a relatively lightweight strategy.

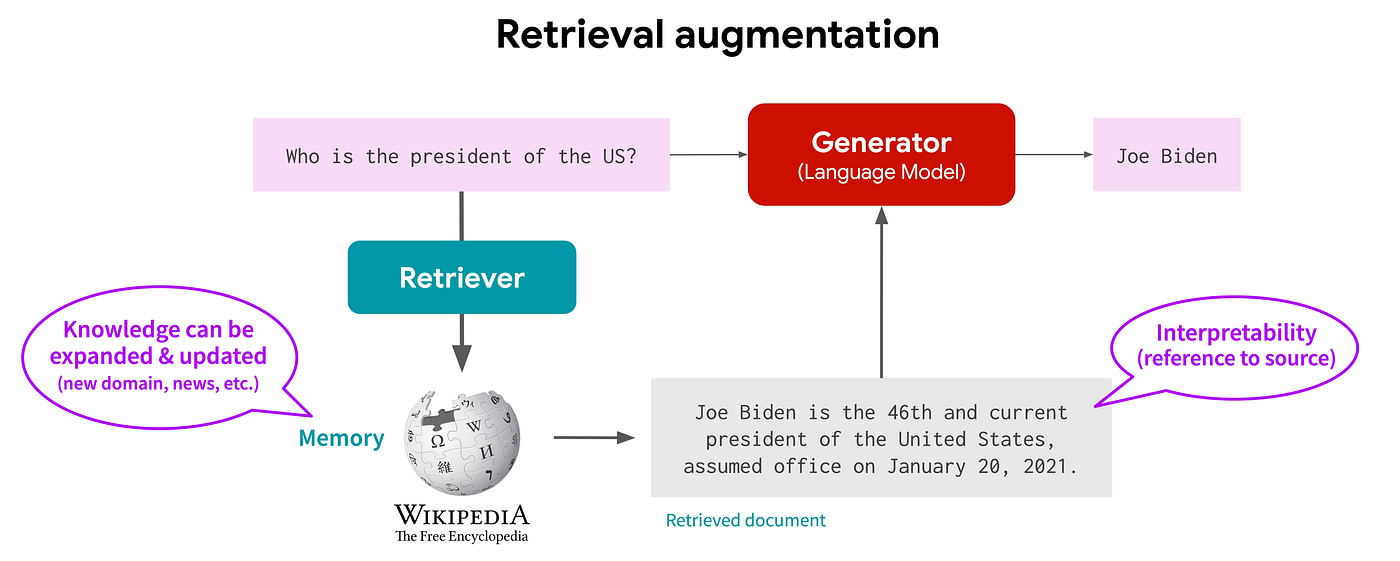
Retrieval Augmented Generation (RAG) to the rescue
One of the main issues with prompt engineering is that the amount of information you can encode into the prompt is limited, determined by the context window size, which is set during training. However, supporting longer context windows can significantly increase both the training and inference costs.
RAG was developed to address this issue. Instead of attempting to encode all the necessary information and input into a lengthy static prompt, RAG favors a prompt template with more dynamic components. The content of these dynamic components is usually a transformation of a retrieved document using an initial search conducted by the user, hence the name ‘retrieval-augmented generation.’ In the context of function calling, RAG allows us to include descriptions only for the functions related to the user’s query, rather than all the functions. When prompted and fine-tuned to focus on the retrieved context, RAG can provide much needed control over the generation thus is widely applied in many applications.
RAG also enables us to use different examples for various user queries, rather than relying on fixed examples. This proves to be more important as it provides a powerful method for hotfixing understanding issues. Using intent detection as an example, when the dialog understanding system fails to comprehend a user’s utterance, instead of initiating a rather expensive fine-tuning process, we can simply add it as a new example to the system. This way, when a similar utterance is encountered by the chatbot again, the new exemplar will be retrieved and included in the generated prompt, which, for the most part, can rectify the misunderstanding on those utterances.
# This is an example of prompt template, which is defined in handlebars.
prompt_template = """
<s> Given the input sentence, construct a function representation
of this sentence, including the function name,
parameters, and their corresponding values. This function
representation should describe the target sentence
accurately and the function must be one of the following
{{#list_skills skills}} {{name}} {{/list_skills}}
.
For each parameter with its value mentioned in the sentence, enclose the parameter and its corresponding values in
brackets. The parameters must be one of the following:
{{#list_slots slots}} {{name}} {{/list_slots}}
The order your list the parameters within the function must follow the order listed above.
Here are a couple of examples.
{{#list_examples examples}} Sentence: {{utterance}} \n Output: {{output}} \n {{/list_examples}}
### Input sentence:
{{utterance}}
### Output:
"""Notice in the above example, we have dynamic components for functions and their descriptions, parameters and their descriptions, and also examples that connect user utterances to target functions. This template can greatly improve the conversion performance to function representation, particularly on smaller models such as TinyLlama-1.1B.
Parting words
The total cost of productionizing any technology comes from two main parts: the initial development and ongoing maintenance. Using only the function description, function calling is a significant reduction for initial dialog understanding development. A RAG based dialog understanding solution can significantly reduce the maintenance cost with its cost-effective hotfixing capabilities. Read on if you want to find out what API we need to support in order to make a RAG based function calling implementation useful for both building tool-using agent and dialog understanding needed by chatbot.
Reference: