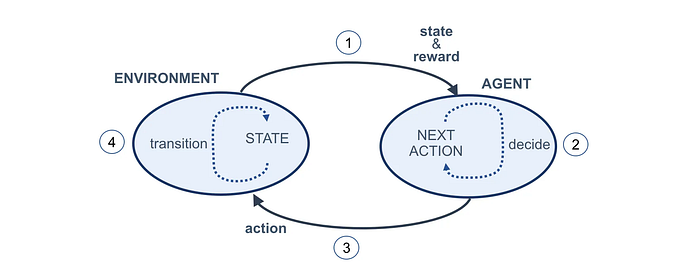
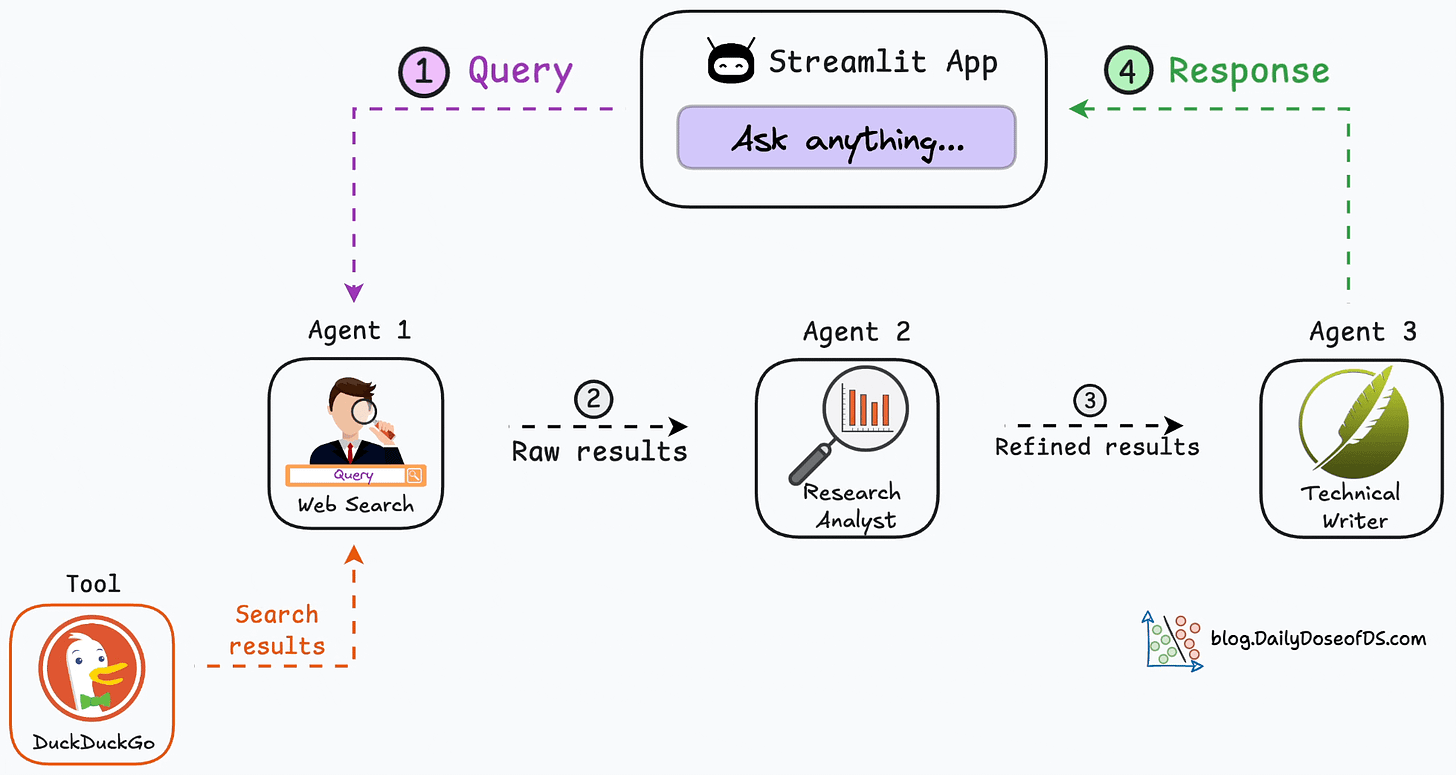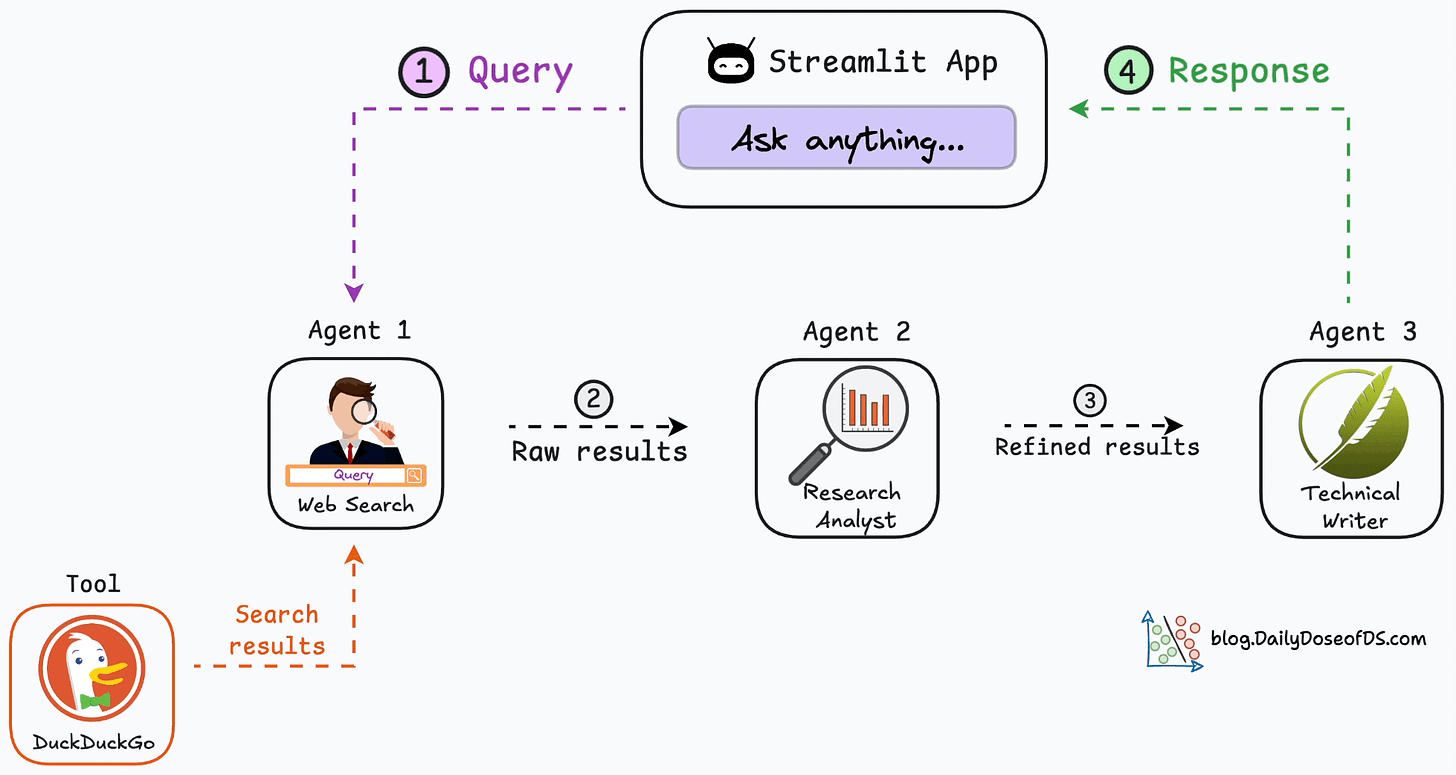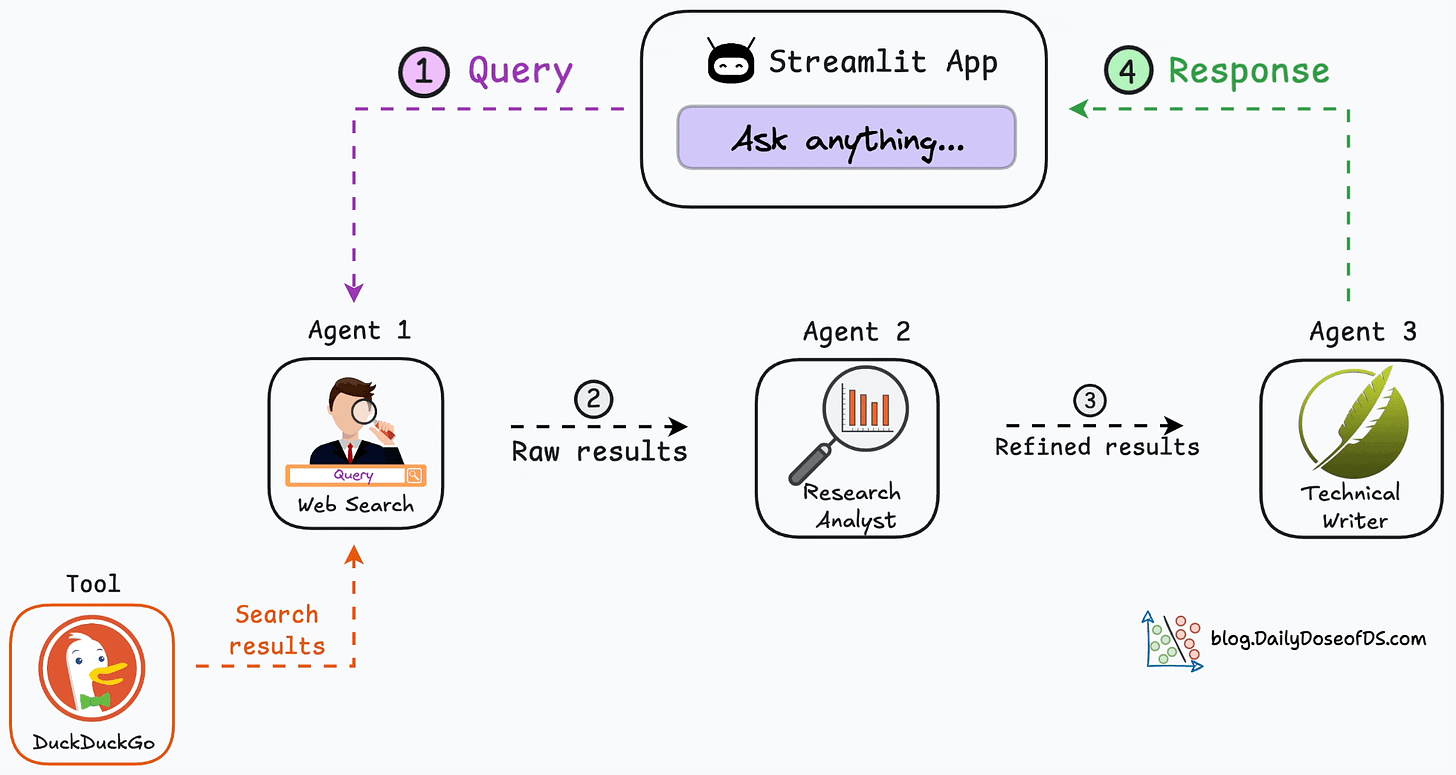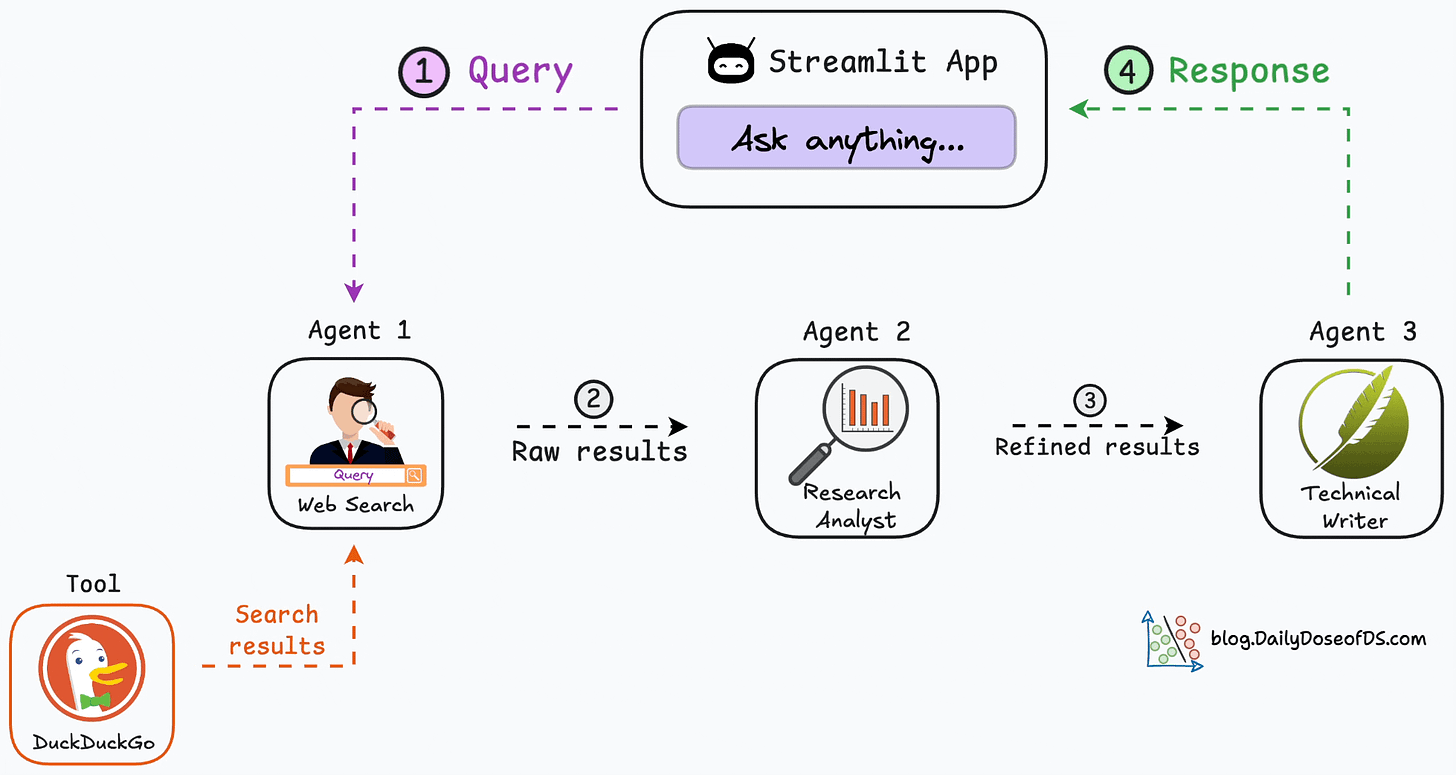
After a year of building demos, more and more people come to realization that trying to build smart application with just one prompt is futile. So, we hear more and more about multi-agent system, and agentic workflow. What are they? In this blog, let’s find out. First let’s review what is prompt.
Prompting is programming

Large language models, with large enough parameters and trained on large body of text (trillions of tokens), can follow natural language instructions. This created a new way of building software: prompt engineering. For example, type this instruction (prompt) into ChatGPT: “Create a multiple-choice quiz question about the water cycle for a 5th-grade science class. Include two correct answers and three incorrect answers.” and you will get:
Questions: Which of the following processes are part of the water cycle?
(Select two correct answers)
a) Evaporation (Correct)
b) Photosynthesis
c) Precipitation (Correct)
d) Combustion
e) TranspirationBuilding software using natural language like this almost feels like magic. Compare to traditional way of building software:

Not only do we not need to learn the syntax and semantics of some programming languages, but we also do not need to know how to write a step-by-step imperative algorithm to solve problems. All we need to do is declaratively describe the problem and the desired outcome, and we are there. It is no wonder that prompt engineering has garnered such interest, and Jensen Huang goes as far as to say that programming is not important anymore.
Prompt engineering and LLMs have their limitations
But then why don’t we have LLM applications everywhere just yet? It turns out that prompt engineering has its limitations.
- The problem-solving capability of a prompt is limited by the underlying LLM’s capability, which is determined by the quality and size of the training data, as well as the number of parameters. Furthermore, when the problem domain is not covered in the training data, the performance can be unpredictable. For example, even the most powerful LLMs make mistakes on simple three-digit multiplication.
- For an LLM to process the input, one needs to encode both the prompt and the input and feed them to the LLMs. On the other hand, the number of tokens that LLMs can effectively process is limited and determined by how the LLMs are trained. For example, LLaMA3 only supports 8k tokens.
- There are research that enables very long input contexts (for instance, Gemini 1.5 Pro accepts 1 million tokens), their ability to truly follow long, complex inputs is questionable. For example, this research reveal the LLM have tendency to “Lost in the Middle” when the input are long.
Unfortunately, there is no easy fix to this. We can increase the number of parameters and tokens used in the pretraining, but that will take too long and cost too much. Some estimate that it will cost $630M to train the Llama3 70B model over 15T tokens on the Azure cloud. Not many businesses can afford that. Short of pretraining, we can fine-tune the base model with increased labeled examples. While it is a lot more manageable, it still requires expertise that can be out of reach for the existing development team. So for regular businesses, do we just wait if the LLM that we can afford to use is not good enough for our use cases?
Divide and conquer to rescue

Divide-and-conquer, decomposing bigger and more complex problems into smaller and easier ones, then composing the solutions to these smaller problems back into a solution for the bigger one, is a cornerstone of effective software engineering practices. It turns out this strategy can also be used to build LLM applications, or agents.
Instead of writing a long prompt that try to solve the problem as a whole, it is possible that we decompose the large problem into smaller ones. By using different prompt for different sub task (using one LLM or multiple different ones), each prompt will be shorter thus easier for LLM to follow. These LLM based software module can then be wired together to solve the original problem. This approach, known as multi-agent system, can drastically increase the performance of the LLM application, as shown in this multi-agent paper from Microsoft.
Adhering to principles
Divides a software application into distinct sections, each addressing a separate concern, improving modularity and maintainability. While it is important to factoring in the insight from the problem domain, it is also important that we follow the tried-and-true software design principles, so that we can ensure that our software is robust, adaptable, and easier to manage over its lifecycle.
- Single Responsibility Principle: The idea is coined by Robert C. Martin, who states that “A module should be responsible to one, and only one, actor.” By making each module focus on one and only one issue, the prompting can be simplified and short, thus easier for LLM to do well. Further more, such modules are easier to reuse.
- Dependency Inversion Principle (DIP): High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details; details should depend on abstractions. Even for LLM modules, there are many different ways a function can be built: zero-shot with a powerful model, few-shot with in-context learning, fine-tuning, and in-context learning with a fine-tuned model. How a particular functionality is implemented should be a separate issue. The client should focus on the contract, or signature, instead of the implementation. This is why newer frameworks like DSPy are very interesting in this regard.
Go Hybrid with Function Calling
While I like the idea of divide and conquer, I do not think it should be called multi-agent. This term is unnecessarily restrictive as it suggests that we must make one agent, or LLM software module, interact with another LLM software module. First, LLMs are not good for everything yet. Second, even when they can be used to solve certain problems, there are sometimes cheaper solutions available. But how can we make LLM-based software modules work with traditional software modules? It turns out it is not that hard.
Because of how they are trained, LLMs have a strong ability to understand and generate text based on context. Even simply using prompting, LLM can be made to translate natural text into structured representation of meaning, in form of JSON and XML. Models that also trained source code tend to perform even better. In fact, OpenAI, and more and more other open source models, have specially been trained to take user query and a list of function descriptions, including the information on their parameter, and spit out the structured representation of meaning. An example of such function description is:
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}For user utterance: “what is the weather going to be like in Glasgow now?", these model can return the function object in structured form like (in OpenAI response format):
ChatCompletionMessageToolCall(
function=Function(
arguments='{
"location": "Glasgow, UK",
"format": "celsius"}',
name='get_current_weather'),
type='function')]
You can check out zero-shot performance of both close and open source models here.
Types of LLM Modules
LLM modules can be classified into the following types based on the nature of their input and output:
- A LLM module takes natural text as input and generate natural text output. Such module can be useful for solving user natural language problem directly, or as a component of that, for example, both retriever and generator in a typical RAG system is of this type.
- A LLM module takes natural text as input and generate structured output. An example of this type is code generation. This type of module is crucial to connect the LLM module with traditional software module. Function calling is one typical example of this type.
- A LLM module takes a date structure, and generate the natural text. This can be useful for chatbot render the structured result from traditional software back to user in natural text.
- A LLM module take structured data, and return structured data as output. This typically requires specialized LLM, for generating promising heuristics for solving extremely difficult problems, like what is used in alpha geometry.
Of course, the classification at this level is not operational. To solve really world problem, we need to define its interface/signature at semantically level. For traditional software, we reply one type system, for natural text input and output module, we need description, and some times, labeled input and output pairs.
Parting words
Solving a problem with a single prompt can be fun and offers a direct way to experience the magic of prompting, provided we are lucky. However, creating a demo is one thing, and building a deployable product is another. To leverage the strengths of LLMs while mitigating their inherent limitations, it is useful to decompose complex tasks into many subtasks. Each subtask can be tackled with a separate prompt or even traditional software engineering. This approach enables us to achieve more reliable and effective outcomes in complex and dynamic environments.
Currently, there are many terms for this approach — multi-agent systems, agentic workflows , or agent engineering— all of which essentially imply solving problems using a divide-and-conquer strategy. This strategy allows for modular design, enabling the development of increasingly sophisticated smart software. With the progress of large language models (LLMs) on standard datasets showing signs of flattening out or plateauing in recent years, instead of waiting for an LLM that can solve your problem out of the box, it is probably wiser to start relying more on strategic planning and using small modules to solve real-world problems effectively. As it works!
Reference:
- “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation” Wu et al. (2023) https://arxiv.org/abs/2308.08155
- https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance/
- https://gorilla.cs.berkeley.edu/leaderboard.html
- https://github.com/stanfordnlp/dspy
- https://towardsdatascience.com/from-prompt-engineering-to-agent-engineering-f314fdf52a25